게임에서 픽셀아트를 뜯어
AI에게 그리는 법 가르치기 — 개발 일지
데이터 수집부터 정제·캡션·학습·후처리까지. 무엇을 시도하고, 무엇이 실패했고, 무엇이 통했는지 — 실제 숫자와 결과로 기록한 여정
무엇을, 어떻게
목표는 Core Keeper 같은 고품질 픽셀아트를 생성하는 AI. 그림 모델 전체가 아니라, 이미 똑똑한
Anima(2B 애니 모델)에 픽셀 화풍만 덧입히는 작은 부품(LoRA)을 학습시킨다. 트리거 키워드는 ssw.
이 일지는 각 단계의 실제 결과와, 막혔던 지점을 어떻게 풀었는지를 담는다.
게임을 직접 받아서 뜯는다
고품질 픽셀아트는 잘 만든 게임 안에 수천 장씩 있다. 보유한 Steam 게임을 steamcmd로 내려받아
엔진별 도구(Unity→UnityPy, XNA→xnbcli)로 스프라이트를 추출했다.

↑ 게임마다 화풍이 조금씩 다르다. 텍스처 이름으로 character/item/environment 자동 분류
임계값 한 줄이 4,300장을 살리다
4.3만 장이 다 쓸만하진 않다. 빈 조각·단색·흐릿한 효과(연기·유령)·시트를 지표로 측정해 걸러냈다 (불투명비율·연결요소·색수·소프트엣지). 시트는 가장 큰 조각 1장만.

↑ 걸러낸 '이질적' 비픽셀 — 글로우·유령·연기. 소프트엣지 비율로 자동 검출
최소 크기 기준을 16px → 8px로 한 줄 바꾸자, Core Keeper가 6,592장으로 회복(소형 스프라이트 +4,300).
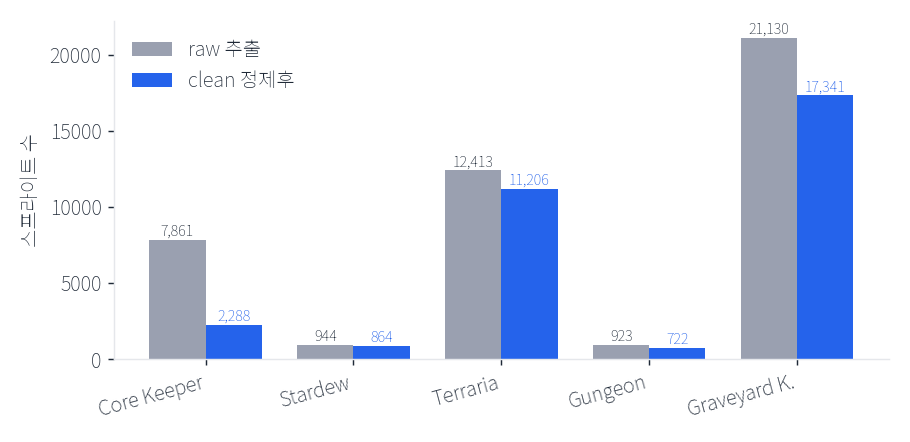
↑ 게임별 원본(회색) vs 정제 후(파랑). 전체 43,271 → 37,490 (87%)
WD 태거의 배신, JoyCaption으로
처음엔 WD tagger(Danbooru 태거)로 태깅했는데, 픽셀 스프라이트가 애니 일러스트 분포 밖이라 "가장 비슷한 태그"로 오매칭했다 — 로봇팔→"sex toy", 갑옷→"1girl/pokemon" 같은 노이즈.
item (무명) → JoyCaption: jar of jam, food, fruitVLM이 실제 내용 파악abstract(실패) → 이름: chain너무 작아 VLM 실패 → 파일명이 보완
↑ 결론: 이름(정답 라벨) + JoyCaption(실제 내용) 결합이 최선. 서로의 약점을 메운다
최종 포맷: ssw, pixel art, simple background, <이름>, <JoyCaption 내용 태그>.
8B VLM이라 단일은 29시간 → 배치 처리로 2.4시간(0.23s/img)으로 단축.
흐림의 원인과 결정적 돌파
Anima에 LoRA(rank32)를 학습. 그런데 첫 1024 결과가 전부 흐릿한 블롭이었다.
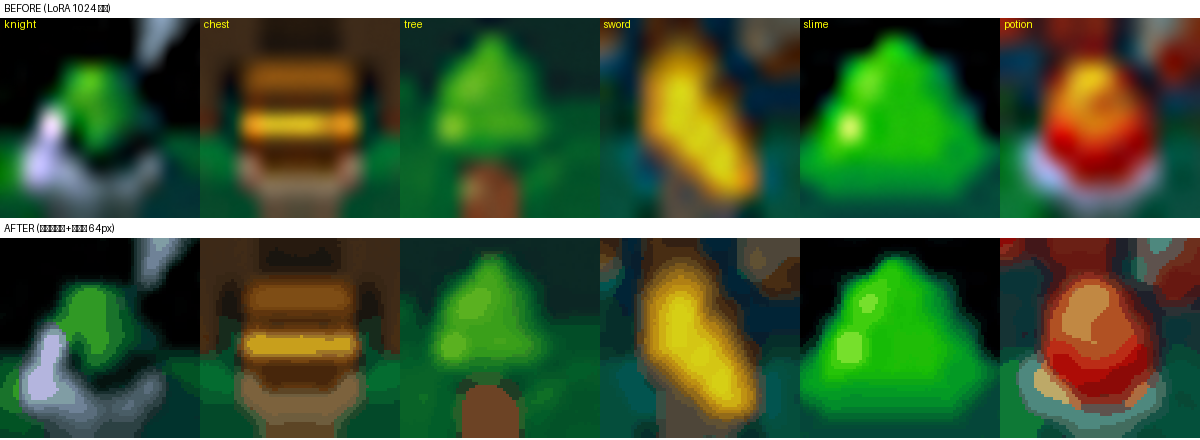
↑ 문제: 인식은 되지만 선명한 픽셀이 아니다

↑ NEAREST+1024 후: 흐린 블롭 → 선명한 기사·상자·슬라임 (step 800→1400)

↑ 최종(step 3000): 게임용 픽셀 스프라이트. 트리거 ssw로 활성화
팔레트와 외곽선
생성물을 게임용 스프라이트로 마무리: ①픽셀화 ②게임 팔레트 스냅(실제 Core Keeper 79만 픽셀에서 48색 추출) ③배경 제거(투명) ④어두운 외곽선(보더라인).

↑ RAW → 픽셀화 → 팔레트 스냅 → 배경제거+외곽선. 체커보드 = 투명(게임 즉시 사용 가능)
핵심 교훈
- 작은 스프라이트는 사전 NEAREST 업스케일 — 보간 업스케일은 픽셀아트를 흐리게 만든다
- 네이티브 해상도를 맞춰라 — Anima는 1024. below-native는 품질 손해
- 투명 PNG는 배경을 명시 — RGB 변환 시 검정 합성됨
- 캡션은 도메인을 탄다 — 애니 태거(WD)는 픽셀에 약함. VLM(내용) + 파일명(정답) 결합이 강하다
- diffusion loss는 평평한 게 정상 — 샘플로 판단
- 임계값 하나가 데이터 수천 장을 가른다 — 항상 측정하고 눈으로 확인
라이브로 보기:
📱 픽셀 에셋 갤러리 🎨 학습 대시보드진행: 수집·정제·캡션(JoyCaption 재작업) 완료 · 통합 LoRA 학습 예정