사진을 보고 문장을 만드는 AI를
바닥부터 만들어 보기
중학생도 이해할 수 있게, 각 단계의 진짜 값을 보면서 따라가는 작은 VLM 이야기
사진을 보고 문장을 만드는 AI
VLM(Vision-Language Model, 비전-언어 모델)은 사진을 보고 그 내용을 말(글)로 설명하는 AI예요. 예를 들어 기린 사진을 주면 "기린이 나무 잎을 먹고 있다"라고 써주는 거죠.
이 AI는 크게 세 개의 부품으로 되어 있어요. 마치 공장의 컨베이어 벨트처럼 사진이 왼쪽에서 들어와 문장이 오른쪽으로 나옵니다.
①번 '눈'은 이미 똑똑한 부품(CLIP)을 빌려 써서 시간을 아끼고, ②③번(번역기와 입)은 우리가 직접 만들어서 학습시킵니다. 이게 이 프로젝트의 핵심이에요.
무엇을 보여주고 가르칠까?
AI도 사람처럼 예시를 많이 봐야 배울 수 있어요. 그래서 사진과 "이 사진은 이런 내용이야"라는 정답 문장이 짝지어진 데이터가 필요해요. 우리는 COCO라는 유명한 사진 모음에서 동물 사진만 골라 받았어요.
animals어떤 분야만 배울지. 여기선 '동물'bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe동물 10종류만 모았어요4000사진을 이만큼만 받아서 학습 시간 단축4000 장실제로 받아진 사진 수3600 / 400연습용(train)과 시험용(val)으로 나눔
↑ 학습에 쓰인 사진 한 장(모델 입력 크기 224×224로 맞춘 모습). 아래가 이 사진에 달린 정답 문장들이에요
· A giraffe is stretching its neck up into a tree.
· A giraffe standing next to a tree surrounded by grass.
· A giraffe standing in the brush, eating leaves from a tree.
· A giraffe on the savannah eating leaves from a tree.사람이 직접 써준 정답 문장 5개 — 이게 '모범답안'
giraffe사진 속 동물 종류(나중에 위치찾기에 사용)한 사진에 정답 문장이 5개나 있는 이유는, 같은 사진도 사람마다 다르게 설명하기 때문이에요. 다양한 표현을 보여주면 AI가 더 유연하게 배워요.
컴퓨터는 그림도 글자도 '숫자'로만 본다
컴퓨터는 사진이나 글자를 그대로 이해하지 못해요. 전부 숫자로 바꿔줘야 합니다.
사진을 숫자로
사진마다 크기가 제각각이라, 먼저 정사각형 224×224로 똑같이 맞춰요 (크기를 줄이고 가운데를 정사각형으로 자름). 그 다음 각 점의 색을 숫자로 바꿔요.

① 원본 사진 (640×425 픽셀) — 가로로 길쭉해요
② 224×224로 변환한 모습 — 모델은 이 정사각형 사진만 봐요
640 x 425 픽셀가로x세로. 사진마다 크기가 달라요[3, 224, 224][색3개(빨강·초록·파랑), 세로224, 가로224]로 통일-1.413 ~ 1.6680~255였던 밝기를 작은 숫자로 바꿈(정규화). 계산이 안정돼요문장을 숫자로 (토큰화)
문장은 토큰이라는 작은 조각으로 쪼개고, 조각마다 번호를 붙여요. 재미있는 건 'Giraffe'처럼 흔치 않은 단어는 통째로가 아니라 조각조각(아래)으로 나뉜다는 점이에요!
↑ 위 칸은 글자조각, 아래 작은 숫자는 그 조각의 번호(token id)
13 개이 문장은 토큰 13조각이 됐어요50256'문장 끝!' 신호 토큰 번호50257빈자리 채우기용 토큰(길이 맞출 때)사진을 단어로 바꾸는 기계 만들기
이제 부품 3개를 조립해요. 숫자 묶음을 '텐서'라고 부르는데, 부품을 지날 때마다 모양(shape)이 바뀌어요. 아래 기린 사진을 넣었을 때의 실제 모양이에요.
[1, 50, 768]사진을 50조각으로 나눈 뒤, 각 조각을 768개 숫자(특징)로 바꿈[1, 50, 512]768 → 512로 바꿔 '입'이 알아듣는 언어로 번역50 개사진에서 나온 '시각 토큰' 수. 단어 50개처럼 취급6층 / 8헤드문장을 만드는 '입'의 두께사진이 어떻게 '50조각'이 될까?
맨 처음엔 정말로 사진을 바둑판처럼 잘라요. 224픽셀 사진을 32픽셀씩 자르면 한 변에 224÷32=7조각, 그래서 7×7=49조각이 나와요. 아래는 실제로 격자를 그려본 모습이에요.

↑ 224×224 사진을 7×7로 자른 모습(1~49번). 단, 이건 '출발점'일 뿐이에요
여기에 사진 전체를 요약하는 특별한 조각 1개(CLS 토큰)를 맨 앞에 더해
49 + 1 = 50조각. 표의 [1, 50, 768]에서 50이 이 수예요.
잠깐 — 그럼 결과는 '잘린 사진 타일'인가요?
아니에요! 좋은 질문이에요. 자르는 건 시작일 뿐이고, 그 다음 두 가지가 일어나요:
- ① 특징으로 압축: 각 조각(픽셀 덩어리)을 768개 숫자로 바꿔요. 이제 '날것의 픽셀'이 아니라 "여기엔 이런 색·무늬·모양이 있다"는 요약(특징)이에요.
- ② 서로 쳐다보기: 조각들이 12단계를 거치며 다른 모든 조각을 참고해 자기 값을 고쳐요(이걸 attention이라 해요). 그래서 '기린 목' 조각은 옆의 '몸통'까지 같이 이해한 특징이 돼요.
그래서 최종 [1, 50, 768]은 '잘린 픽셀 타일'이 아니라 '이미지 특징(feature)'이에요.
격자 그림은 그 50이 어디서 나왔는지를 보여줄 뿐, 결과는 네 말처럼 feature가 맞아요.
그 '특징'을 눈으로 볼 수 있을까?
먼저 짚을 점: 이 숫자 768개는 패치(칸) 1개의 특징이에요. 224×224 사진 전체가 아니에요! 패치가 49개니까 768숫자 묶음도 49개 있어요. (사진 전체를 요약하는 건 따로 있는 50번째 'CLS' 칸이고, 아래 색칠에는 안 넣었어요.) 아래에서 패치 1칸이 어떻게 색 1개가 되는지 봅시다.

↑ 빨간칸 패치 1개(32×32픽셀, 변환 전) → 숫자 768개 → 오른쪽 같은 칸의 색 1개(변환 후)
패치 하나의 색은 어떻게 정해질까?
색은 PCA라는 방법으로 정해요. 49개 패치의 768숫자를 보고 가장 차이가 크게 나는 방향 3개를 찾아, 각 패치를 그 3방향으로 재서 나온 숫자 3개를 빨강·초록·파랑에 넣어요. 그래서 특징이 비슷한 패치는 색도 비슷해져요.
진짜 그런지 패치 3개로 확인해봤어요(유사도 = 768숫자 전부로 잰 값, 1에 가까울수록 비슷):

↑ A·B는 유사도 0.95 → 색이 거의 같음. A·C는 0.38 → 색이 완전히 다름
그럼 색이 다르면 무조건 다른 특징일까? 꼭 그렇진 않아요. 색은 768숫자를 3개로 확 줄인 요약이라, 버려진 방향에서는 비슷할 수도 있어요. 그래서 진짜 유사도는 768개를 다 쓰는 아래 ③ 방법이 더 정확해요. ②(색)는 '눈으로 보는 대략 지도', ③은 '정밀 측정'인 셈이에요.
이걸 49칸 전부에 적용한 게 아래 ② 그림이에요. 두 가지로 특징을 엿볼게요.

↑ ① 모델이 본 사진 · ② 특징을 색으로(PCA) · ③ ★조각과 비슷한 특징을 가진 곳
- ② 특징을 색으로(PCA): 비슷한 특징이면 비슷한 색. 하늘·기린·풀밭이 서로 다른 색 덩어리로 나뉘어요. (색 자체는 의미 없고 '같은 색=비슷한 특징'이 핵심)
- ③ 비슷한 곳 찾기: 기린 몸통 조각(★)과 특징이 비슷한 조각을 빨갛게. 기린 부분이 함께 빨개지고 배경은 파래요 — 모델이 '기린다움'이라는 의미로 묶는 증거.
단, 우리 사진은 7×7=49칸으로 굵게 나뉘어 그림이 좀 거칠어요. 그래도 "비슷한 특징끼리 모인다"는 건 분명히 보이죠.
무엇을 학습하나?
전체 132.8M개 손잡이 중 45.3M개만 우리가 돌려요. 나머지 87.5M개(눈)는 고정! 그래서 학습이 빠릅니다.
87.5M 개이미 똑똑해서 건드리지 않음(학습 안 함)45.3M 개번역기+입. 이것만 우리가 학습132.8M 개전부 합친 크기틀리면서 조금씩 똑똑해지기
학습은 "다음에 올 단어 맞히기" 연습이에요. 사진과 문장 앞부분을 주고 다음 단어를 맞혀보게 한 뒤, 틀린 만큼 손잡이를 살짝 돌려 고쳐요. 이걸 수만 번 반복해요.
10.82아무것도 모를 때. 찍기 수준이라 점수가 나쁨(높음)3.139연습 후. 훨씬 낮아짐 = 정답을 잘 맞힘2.5415시험용 사진에서의 점수. 낮을수록 좋아요20 회전체 사진을 20번 반복해서 봄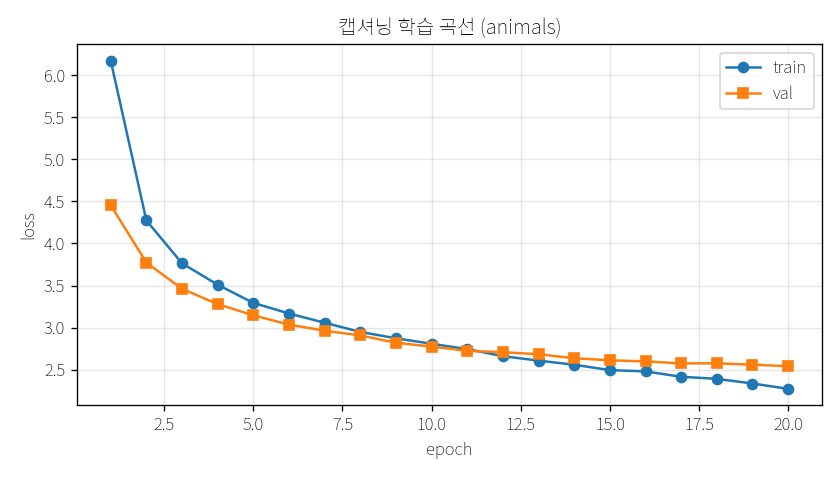
↑ 가로는 연습 횟수(epoch), 세로는 loss. 선이 내려갈수록 똑똑해진 거예요
처음엔 loss가 10.82(찍기 수준)이었는데 연습 후 2.5415까지 내려갔어요. 숫자가 작아진 만큼 똑똑해진 거예요.
한 단어씩, 끝 신호가 나올 때까지
완성된 AI에게 새 사진을 보여주면 문장을 만들어요. 한 번에 통째로가 아니라 한 단어씩 만들고, 그 단어를 다시 넣어 다음 단어를 만들어요. '문장 끝!' 신호가 나오면 멈춰요.
아래 사진(000000005694.jpg)을 AI에게 보여주고 실제로 생성한 순서예요
(총 12단계):

↑ AI가 처음 보는 사진. 이 사진을 보고 아래처럼 한 단어씩 만들어요

↑ 검증 사진들에 대해 AI가 만든 문장(생성)과 사람 정답(정답) 비교
A bird is standing on the branch of a tree.우리 모델이 스스로 만든 것!A white parrot standing next to a jungle covered hillside.모범답안AI는 흰 앵무새를 보고 "A bird is standing on the branch of a tree(새가 나뭇가지에 서 있다)" 라고 했어요. 정답과 똑같진 않지만 '새', '나무'를 알아본 거예요. 바닥부터 만든 작은 모델치고 훌륭하죠!
해냈어요! 그리고 다음은?
사진을 보고 문장을 만드는 AI를 바닥부터 만들어 학습시키고, 실제로 동물 사진을 설명하게 했어요. 다음으로 도전할 수 있는 것들:
- ✅ 위치 찾기(detection): "기린이 여기에 있다"처럼 네모 상자 좌표까지 글자로 말하게 만들기 → 위치 찾기 페이지에서 직접 보기
- ✅ CLIP — 다른 길: 글자를 만드는 게 아니라 사진과 글자를 같은 공간에 놓기 → SmallCLIP 페이지에서 직접 보기
- 차량 버전: 같은 방법으로 자동차 사진도 설명하게 하기
동물 captioning · 검증 BLEU 23.10 · 학습 약 수 분