사진과 글자를 같은 공간에 놓기
SmallCLIP 직접 만들기
CLIP의 구조(투 타워 + 공유 공간 + 대조 학습)를 그대로 계승해서 작게 직접 만들어 본 이야기
'사진 만들기' 대신 '사진과 글자를 짝짓기'
앞에서 만든 캡셔닝 모델은 사진을 보고 문장을 만들었어요. CLIP은 다르게 접근해요. 사진과 글자를 둘 다 같은 자리(공유 공간)에 놓고 가까운 쌍은 가깝게, 다른 쌍은 멀게 배워요.
이걸 한 번 만들어 두면 놀라운 일들이 가능해져요: (1) zero-shot 분류 — 분류 학습을 안 했는데 "a photo of a cat"이란 글자만으로 사진을 분류함. (2) 검색 — 글자로 묘사하면 비슷한 사진을 찾아줌. CLIP의 진짜 매력이에요.
이미지와 글자를 같은 자리로 보내기
CLIP은 부품이 두 개예요. 이미지 인코더와 텍스트 인코더가 각자 자기 입력을 받아 같은 차원의 벡터로 변환해요. 그 자리(공유 공간)에서 둘이 만나요.
256이미지와 텍스트가 만나는 곳. 둘 다 L2 정규화 → 코사인 유사도 계산16.4M 개frozen CLIP(87.5M)은 안 건드리고 텍스트 인코더+projection만N×N 표 만들고 대각선만 1로
한 번 학습할 때 사진과 글자를 256쌍씩 묶어요. 각 사진과 각 글자의 유사도를 모두 재면 256×256 표가 만들어져요. 정답은 같은 줄·같은 열(대각선)이 가장 높고, 나머지는 낮아야 해요.
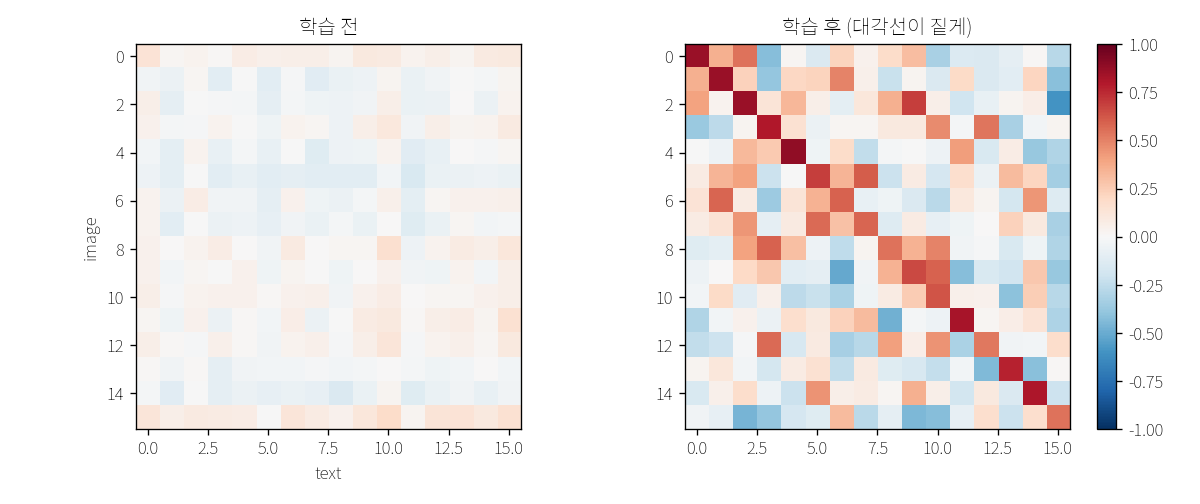
↑ 빨강=가까움, 파랑=멂. 학습 전은 골고루(랜덤), 학습 후엔 대각선만 진한 빨강이 됨
이걸 숫자로 표현한 게 대조 학습 손실(contrastive loss)이에요. 사진→글자 방향, 글자→사진 방향 둘 다 "정답은 대각선이야"라고 cross-entropy로 가르치고 평균.
대각선이 얼마나 잘 드러났나
5.55ln(256). 아무것도 모를 때 손실값2.0892이 값까지 떨어짐(낮을수록 좋음)42.0%256개 중 정답 캡션을 1위로 맞힌 비율18 회전체 20회 중 best 시점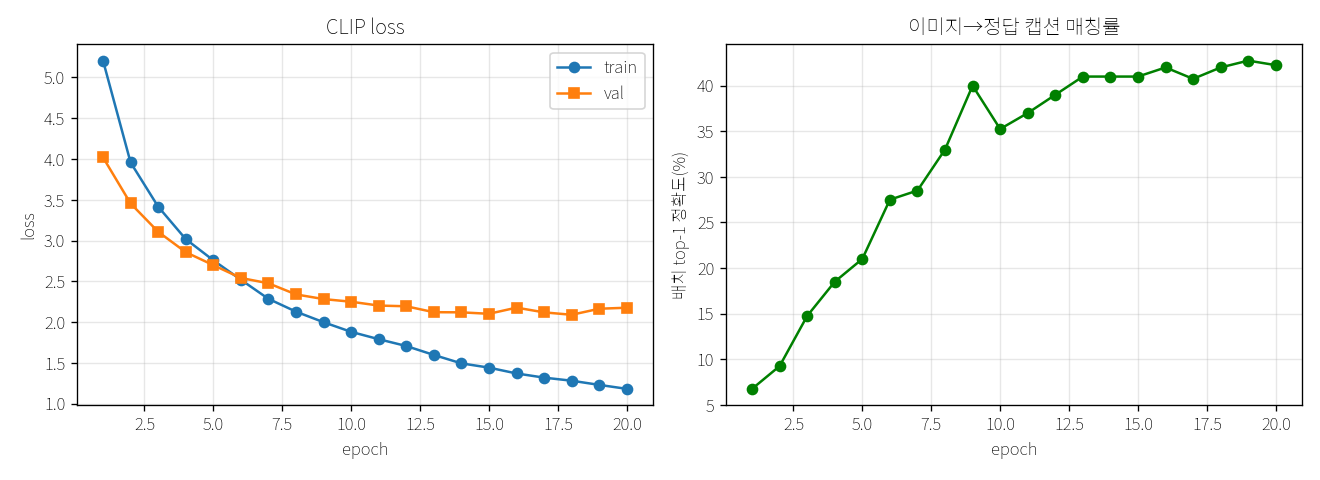
↑ 왼쪽=loss(낮을수록 좋음), 오른쪽=배치 매칭 정확도(높을수록 좋음)
분류 학습 안 했는데 분류가 된다?!
CLIP의 마법: 분류 task를 따로 학습 안 했는데도, "a photo of a cat" 같은 글자만
주면 사진의 정체를 맞혀요. 글자 임베딩 10개(bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe)와
사진 임베딩의 코사인 유사도가 가장 큰 글자가 답.

↑ 9가지 동물 zero-shot 분류. 초록=맞춤, 빨강=틀림
검증셋 400장에 대해 전체 77.8% 정답. 10종 랜덤이면 10%인데 그보다 한참 위예요. 학습 데이터가 작은데도 '기린이라는 의미'를 이미지와 글자가 공유하게 됐다는 증거.
"갈색 곰" 같은 글로 사진 찾아내기
같은 원리로 검색이 돼요. 글자 한 줄(쿼리)을 임베딩하고, 모든 검증 이미지 임베딩과 비교해 가까운 순으로 정렬. 학습 데이터엔 없는 표현도 일반화돼요.
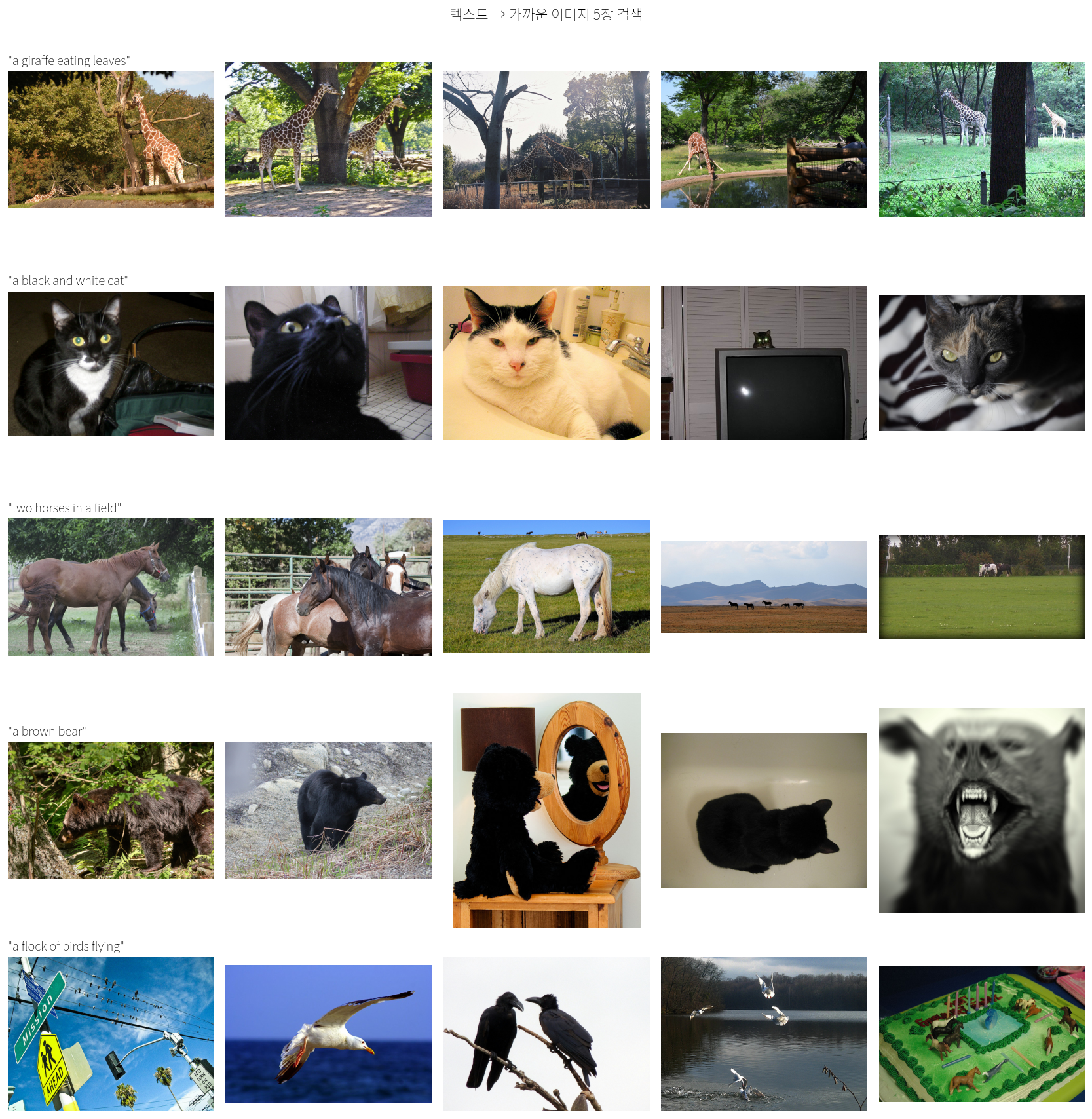
↑ 각 줄: 왼쪽 글자로 검색했을 때 가까운 사진 5장 (학습 안 본 검증셋에서)